Disambiguation is a word I stole from Wikipedia. Cambridge Dictionary describes it as “The fact of showing the differences between two or more meanings clearly.” For instance, when you search an encyclopedia for a person’s name, the author of that reference needs to know which specific person you want to locate, and it has to be based on criteria something like birth and death dates. Let’s say you want to learn about John Adams. OK, fine… but which one? That is why I like using the word disambiguation regarding family trees. If you are studying family histories from England, the number of children named John, Thomas, Edward, Michael, Nathaniel, Samuel and Joseph for men, or Elizabeth, Mary, Sarah, Patricia, Hannah and Sarah for women, can be mind-boggling. The Puritan immigrants changed it up a bit by adding in even more names like Prudence, Temperance, Charity, Love and… Wrestling? But then, every generation, the next set of children used that same set of names for their kids, and so on and so on. So cousins born on similar dates in about the same area can be easily confused.
The good news is that we now have an online repository of information which was originally researched the good, old-fashioned way… going to libraries and finding primary sources written during the “Great Era of Antiquarianism” in the 19th Century, to celebrate pride in the accomplishments of one’s ancestors who endured hardships but persisted to success, building our “modern world.” When added to the physical documentary sources of family history such as the inside covers of Family Bibles and oral remembrances by family elders, there was a growing amount of solid information available to genealogists.
We are now in the digital era, and all of that printed material can be scanned electronically, using Optical Character Recognition. Both Google and Microsoft have underwritten huge projects to make historic printed information available online. Obviously, error checking has to be done, But that is easy, compared to what it takes to transcribe handwritten information, like our decennial U.S.Census. Deciphering the handwriting of the thousands of human enumerators used in the US since 1790, for both Federal and State Census materials is overwhelming to think about. The LDS Church has had a huge and ongoing program dedicated to exactly this in operation for years. There is an interesting article about this in Mother Jones magazine.
Using the database in Ancestry is easy… perhaps too easy. My number one rule about adding a person to a search is: slow down… and fill in as much as you can, even including making educated guesses. I know that this might seem horrifying to real genealogists who have been so precise for so many years, but the more fields the database can search on simultaneously, the higher the probability of success. For instance, if you are looking for the parents of one of your relatives, if you don’t know their birth date, enter a year which is 20 years previous to the birth date of the person who is their child. Same thing goes with locations. For most of history until the 19th century, people generally lived near when their parents were born. It’s a good place to start, at least. When you finally press the “search” button, your number of possible correct results just increased exponentially.
This is where the famous Ancestry “hints” come from. Using Artificial Intelligence, it comes up with suggestions from all the records databases to which it has access, plus at the top of every set of hints, there is usually always one which has searched other user family trees to come up with a number of them that you can “borrow” data from. It’s a 2 step process. You get to review the data, then click on accept. First of all, despite the temptation, do not go to another the other user trees first. Do it the other way around. I like to start with the Census data, from whichever country you are checking. And make sure to click on the “View Source” button! There is always important data that either isn’t transcribed, transcribed incorrectly, or doesn’t get transferred into your tree when you click. Once you have added in the the database hints (the ones which make sense), only then should you look at the hints from other people’s tree.
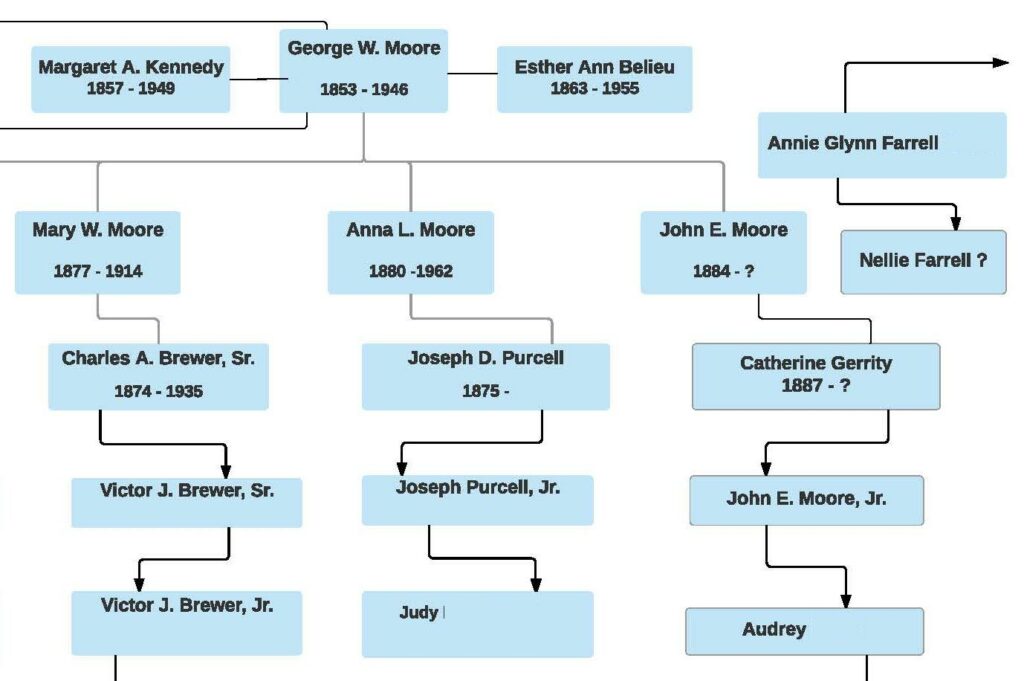
It is just waaaaay too tempting to look at all the data other people have in the tree already, and click on “Accept,” because you have nothing there in your tree yet, and this looks like a really simple solution. There is no guarantee that they are right, and just because a number of people have the same info, that doesn’t necessarily make it more true. I say this as a voice of experience, because I myself have also helped perpetuate bad information in the past. The reason this chapter is entitled “Disambiguation,” is because I have had to to back and correct the mistakes other people have made, which I just sucked into my own tree without being careful. That is what happened during my George W. Moore conundrum. I had to go back in and pry apart, bit by bit, what data was applicable to which person. It was like trying to peel off one of those SciFi alien creatures that had latched onto someone’s face. I also say this admitting that the “simple” Moore Family Tree I posted earlier was actually wrong. There is a wrong wife in there. It was becoming easier to see now that the reason that my Irish cousin cloud was so big, was not only because George Moore had a lot of children… he had them with multiple wives… hopefully sequentially. I just had to figure our which were correct. Disambiguation time!